(이게 왜 레벨 2가 아닌 레벨 1일까요?..)
문제
두 숫자 X, Y가 주어질 때 X와 Y에 공통으로 있는 숫자를 모두 찾아서 그 숫자들을 조합하여 만들수 있는 최댓값을 리턴하는 함수를 작성한다.
같은 숫자가 중복되어 있을 경우 중복된 개수만큼 붙인다.
해결과정
처음엔 문제를 잘못 이해하고 중복을 없애려고 Set을 사용했다가 문제를 잘못 이해한 것을 인지하고 List로 바꿔서 구현했었습니다. ㅎ
그러나 List를 사용 시 몇 가지 테스트에서 통과를 하지 못하여 갈아엎고 ㅎ 배열로 풀었습니다. 😂
입력받은 String을 각각 char형 배열로 변환한 후 오름차순으로 정렬을 했습니다.
오름차순으로 각각 정렬한 이유는 0번 인덱스부터 배열의 끝까지 비교하면서 공통으로 있는 수를 찾으려 했기 때문입니다.
우선은 두 개의 배열을 반복문에서 동시에 순회하면서 비교할 것이기 때문에 index를 담을 변수를 선언 후 0으로 초기화해줍니다.
저는 반복문으로 for문이 아닌 while문을 사용하였는데 따로 x, y 인덱스 변수가 있기 때문에 인덱스를 증가시켜줄 필요가 없어 조건만 넣은 while 문을 사용하였습니다.
while 문의 조건은 'x인덱스가 x배열의 길이 보다 작고 y인덱스가 y배열의 길이보다 작다'로 설정하였습니다.
이미 x배열과 y배열은 정렬이 되어 있기 때문에 앞에서부터 비교하면서 값이 더 작은 배열의 인덱스의 값을 올려주었습니다.
그리고 값이 같을 경우 해당 값을 StringBuffer에 붙여주고 두 배열의 index를 동시에 증가시켜주었습니다.
(StringBuffer를 사용한 이유는 오름차순을 내림차순으로 바꿔주기 위해 reverse()를 사용할 것이기 때문입니다!)
이렇게해서 하나의 배열이라도 맨 끝에 다다르면 반복을 중지합니다.
이렇게 되면 모든 공통값이 오름차순으로 들어가게 되서 reverse()를 해줍니다.
여기까지만 작성하고 리턴하게 되면 몇가지를 통과하지 못하게 되는데..
0만 있을 경우엔 (예를 들어 "000" 같은 경우) "0"으로 변환해주어야 합니다.
만약에 결과 문자열에 0만 있다면 내림차순이기 때문에 맨 앞에 0이 올 것입니다.
따라서 맨 앞의 문자가 0인지 조건문으로 확인하여 0이라면 "0"만 리턴하면 됩니다.
이렇게 배열로 하면 시간복잡도가 O(n)으로 나쁘진 않은 편? 입니다. (이보다 좋은 방법이 있겠지만 떠오르지 않았습니다.)
코드
import java.util.Arrays;
import java.lang.StringBuffer;
class Solution {
public String solution(String x, String y) {
StringBuffer answer = new StringBuffer("");
char[] xArr = x.toCharArray();
char[] yArr = y.toCharArray();
Arrays.sort(xArr);
Arrays.sort(yArr);
int xIdx = 0;
int yIdx = 0;
while (xIdx < xArr.length && yIdx < yArr.length) {
if (xArr[xIdx] == yArr[yIdx]) {
answer.append(String.valueOf(xArr[xIdx]));
xIdx++;
yIdx++;
} else if (xArr[xIdx] < yArr[yIdx]) {
xIdx++;
} else if (xArr[xIdx] > yArr[yIdx]) {
yIdx++;
}
}
if (answer.length() < 1) return "-1";
answer.reverse();
String result = answer.toString();
if (result.charAt(0) == '0') return "0";
return result;
}
}
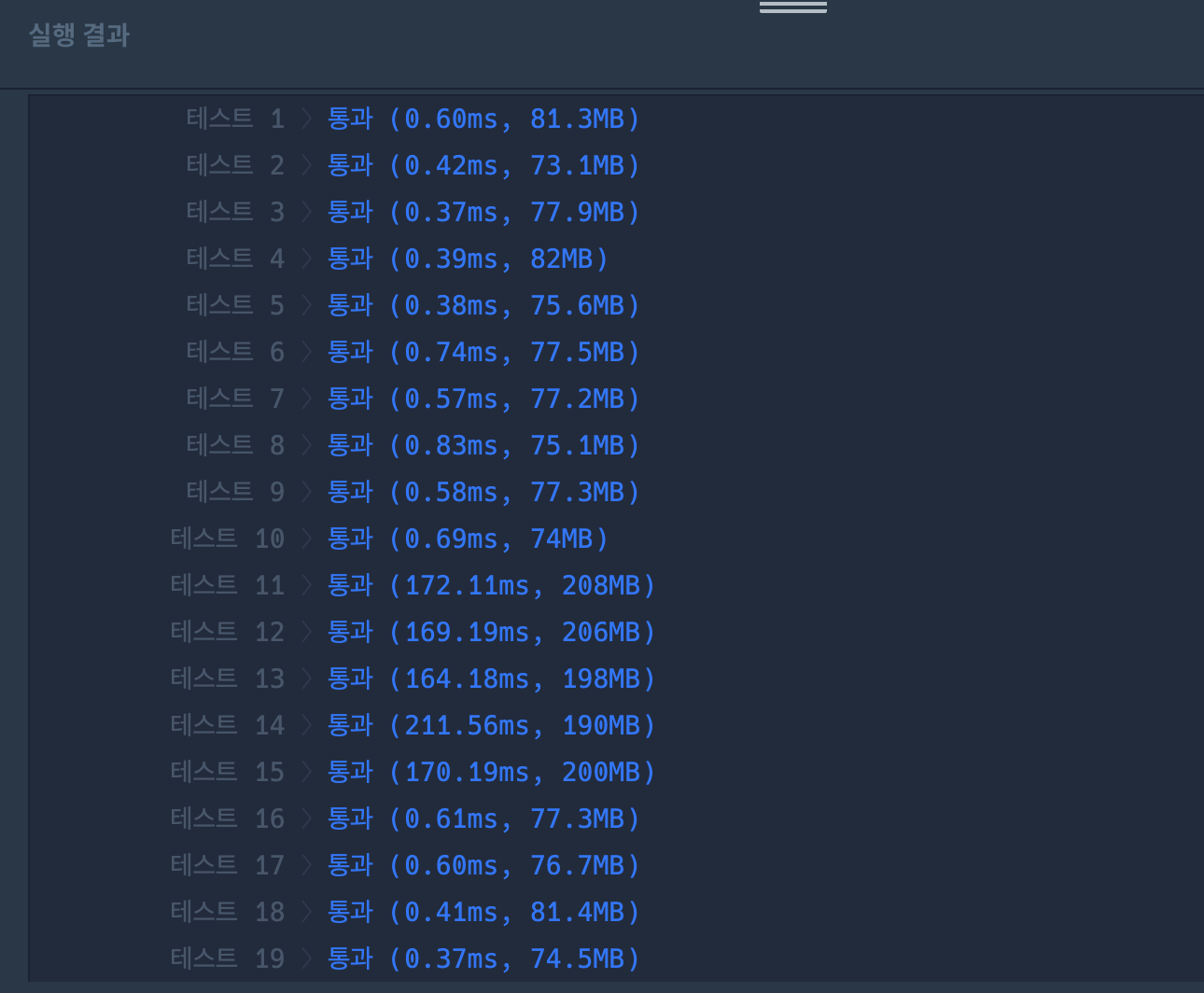
실행 결과
읽어주셔서 감사합니다. 🤗 좋은하루 되세요~
'JAVA > 해결한 문제' 카테고리의 다른 글
| [Java/알고리즘] Merge Sort (병합 정렬) (0) | 2022.10.26 |
|---|---|
| [Java/알고리즘] 성격 유형 검사하기(프로그래머스 Lv.1) (0) | 2022.10.25 |
| [Java/알고리즘] Quick Sort(퀵 정렬) (0) | 2022.10.24 |
| 소수(prime number)인지 구하는 함수 구현하기 (3) | 2022.06.13 |
| CC(Coin Change, 동전교환) 알고리즘 구현하기 (0) | 2022.06.06 |