public class EnergyController {
public static void main(String[] args) {
MonsterDrink monsterDrink = new MonsterDrink();
int energy = monsterDrink.getCaffeine();
}
}
public class MonsterDrink {
public int getCaffeine() {
return 10;
}
}
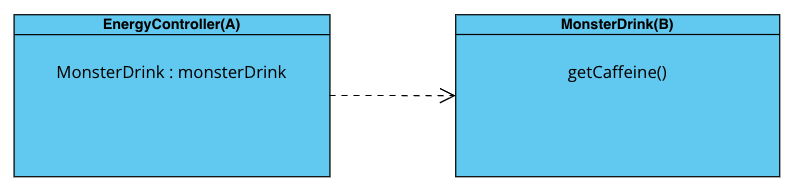
위 코드에서 EnergyController 클래스는 클라이언트로부터 요청을 받는 엔드포인트(Endpoint) 역할을 한다.
그리고 MonsterDrink 클래스는 EnergyController 클래스가 전달받은 클라이언트의 요청을 처리하는 역할을 한다.
클라이언트 측면에서 서버의 엔드포인트란 클라이언트가 서버의 자원(리소스)를 이용하기 위한 끝 지점을 의미한다.
EnergyController에서 에너지드링크인 MonsterDrink 객체를 생성한 후 MonsterDrink의 getCaffeine() 메소드를 호출하고 있다.
이처럼 객체를 생성해서 참조하게 되면 의존 관계가 성립하게 된다.
그러나 두 클래스간의 의존 관계가 성립됐지만 아직 의존성 주입은 이루어지지 않았다.
의존성 주입을 하기 위해 코드를 수정해보자.
public class EnergyController {
public static void main(String[] args) {
MonsterDrink monsterDrink = new MonsterDrink();
PresentEnergy presentEnergy = new PresentEnergy(monsterDrink);
int energy = monsterDrink.getCaffeine();
}
}
public class MonsterDrink {
public int getCaffeine() {
return 10;
}
}
public class PresentEnergy {
private MonsterDrink monster;
public PresentEnergy(MonsterDrink monster) {
this.monster = monster;
}
}
의존성 주입은 생성자를 통해서어떤 클래스의 객체를 전달 받는 것이다.
생성자의 매개변수로 객체를 전달하는 것을 외부에서 객체를 주입한다고 표현하는 것이다.
그렇다면 여기서 외부는 어디일까?
객체를 매개변수로 전달하고 있는 클래스가 외부이다.
클래스의 생성자로 객체를 전달받는 코드가 있다면 객체를 외부에서 주입받고 있어서 의존성 주입이 이루어지고 있다고 볼 수 있다
▶️ 왜 의존성 주입이 필요한가?
자바에서 생성자를 통해 객체를 전달하는 일은 아주 흔한 일이다.
하지만 의존성 주입을 사용할 때 클래스 내부에서 외부 클래스의 객체를 생성하기 위한 new 키워드를 사용을 지양해야 한다.
객체를 생성할 땐 당연히 new 키워드를 쓰지만 *Reflection이라는 기법을 이용해서 Runtime시에 동적으로 생성할 수 있는 방법이 있다.
new 키워드를 사용해서 의존 객체를 생성할 때, 클래스들 간의 강하게 결합(Tight Coupling)되어 있다고 한다.
하지만 자주 변경하려면 클래스들 간의 강한 결합은 피하는 것이 시간을 절약할 수 있다.
따라서 강한 결합보다는 느슨한 결합(Loose Coupling)을 사용하는 것이 좋다.
애플리케이션의 요구사항은 언제나 바뀔 수 있기 때문에 코드를 작성할 때 이부분을 고려하는 것이 좋다.
▶️ 느슨한 의존성 주입은 어떻게 할까?
클래스 간의 관계를 느슨하게 하는 대표적인 방법은 바로 인터페이스(Interface)를 사용하는 것이다.
어떤 클래스가 인터페이스 같이 일반화된 구성 요소에 의존하고 있을 때, 클래스들 간의 느슨하게 결합되어 있다고 한다.
예시로 작성했던 코드는 전달할 객체를 생성할 때 new 연산자를 사용했기 때문에 강하게 결합되어 있다.
그런데 여기서 에너지드링크를 monster가 아닌 hotsix로 바꾼다고 하면 코드를 수정할 부분이 많아진다.
하지만 monster와 hotsix의 일반적인 개념인 EnergyDrink라는 인터페이스를 만들어서 monster를 사용한 부분에 EnergyDrink를 작성한다면 어떨까?
moster와 hotsix 중 전달하고 싶은것을 생성할 때 작성하기만 하고 나머지는 수정하지 않아도 된다.
위의 내용을 코드로 구현하면 아래와 같다.
public class EnergyController {
public static void main(String[] args) {
EnergyDrink energyDrink = new MonsterDrink();
PresentEnergy presentEnergy = new PresentEnergy(energyDrink);
int energy = energyDrink.getCaffeine();
}
}
public interface EnergyDrink {
public int getCaffeine();
}
public class MonsterDrink implements EnergyDrink {
@Override
public int getCaffeine() {
return 10;
}
}
public class Hotsix implements EnergyDrink {
@Override
public int getCaffeine() {
return 7;
}
}
public class PresentEnergy {
private EnergyDrink energyDrink;
public PresentEnergy(EnergyDrink energyDrink) {
this.energyDrink = energyDrink;
}
}
하지만 여전히 EnergyController 클래스 내에서 객체를 생성할 때 new 연산자를 사용하고 있다.
여기서 이 new 연산자는 어떻게 없앨 수 있을까?
▶️ Spring 에서 의존성 주입을 누가 해주는가?
Spring에서 new 키워드로 객체를 생성하지 않고 Spring이 그 역할을 대신 할 수 있다.
new 키워드를 없애려면 Config라는 클래스를 이용하면 된다.
Config에 대해선 차후에 자세히 학습할 예정이기 때문에 지금은 어떤 역할인지만 기억하고 넘어가자.
Config클래스는 객체 생성을 미리 정의해 둔다.
그래서 Spring의 도움을 받아 new 키워드 마저도 없앨 수 있다!
하지만 Config클래스 객체를 new 키워드로 생성한거면 이것도 문제이지 않을까??
아니다. Config 클래스는 단순한 클래스가 아니라 Spring Framework의 영역에 해당하는 것이고 Config 클래스가 실제 애플리케이션의 핵심 로직에 관여하지 않고 있기 때문에 문제가 되지 않는다.
Spring 기반의 애플리케이션에서는 Spring이 의존 객체들을 주입해주기 때문에 애플리케이션 코드를 유연하게 구성할 수 있다.
원하는 Spring Boot 실행 환경과 필요한 모듈을 포함하는 템플릿 프로젝트를 생성해 준다.
Spring Boot 애플리케이션은 WAS 배포용인 War 파일 형태로 배포할 수 있지만, 일반적으로 Spring Boot 애플리케이션은 WAS를 내장하고 있는 Jar 파일 형태로 배포해서 실행한다.
스프링 != 스프링 부트
스프링 부트는 스프링을 잘 활용하기 위해 스프링에서 나온 프로젝트
Packaging : 개발한 코드를 빌드해서 하나의 결과물로 만들어 낸다
ADD DEPENDENCIES 에서 ‘Lombok’ 과 ’Spring Web’을 선택하고 GENERATE를 누른다.
그러면 zip 파일이 다운로드 된다.
다운로드한 zip 파일은 압축해제 한다.
그 다음에 intelliJ에서 Open으로 압축을 푼 프로젝트를 열면 된다.
❑ Spring Framework 소개
➤ Framework란?
Frame은 틀, 구조, 뼈대 등의 의미이다.
벽에 거는 액자를 프레임이라고 부르기도 한다.
자동차에서는 뼈대가 되는 강판을 프레임이라고 부른다.
이처럼 Frame은 어떤 대상의 큰 틀이나 외형적인 구조를 의미한다.
지금까지 배웠던 것 중에 Framework는 Collections Framework가 있다.
Collections Framework 안에 있는 Map, Set, List 등은 데이터를 저장하기 위해 자주 사용되는 자료구조를 바탕으로 자바에서 제공하는 클래스이다.
그렇다면 콜렉션에 왜 framework라는 말을 붙일까?
자바에서 framework, 틀 하면 제일 먼저 생각나는 것이 인터페이스(Interface)이다.
자바의 콜렉션은 Map, List, Set같은 인터페이스와 그 인터페이스를 구현한 구현체들의 집합이다.
이렇게 Framework는 프로그래밍을 하기 위한 기본적인 틀이나 구조를 제공한다.
그 외에도 프레임워크는 다양한 기능들을 제공한다.
개발하고자 하는 애플리케이션이 다른 애플리케이션과 통신하고 데이터를 데이터 저장소에 저장하는 등의 기능들도 프레임워크나 라이브러리에서 제공한다.
이를 통해 개발자는 애플리케이션의 핵심 로직을 개발하는 것에만 집중할 수 있도록 해준다.
➤ Framework 와 Library?
프레임워크와 라이브러리는 얼핏 보면 같은 개념이지만 차이점이 있다.
프레임워크와 라이브러리는 여러가지 필요한 기능들을 제공한다는 점에서는 비슷하지만 중요한 차이점이 바로 애플리케이션에 대한 제어권이다.
라이브러리는 애플리케이션 흐름의 주도권이 개발자에게 있다.
개발자가 짜 놓은 코드내에서 필요한 기능이 있으면 호출해서 자유롭게 사용이 가능하다.
이에 반해 프레임워크는 애플리케이션 흐름의 주도권이 개발자가 아닌 프레임워크에 있다.
프레임워크는 불러오면 코드 상에서 보이지 않는 상당히 많은 일들을 한다.
개발자가 메서드내에 코드를 작성해두면 스프링 프레임워크에서 개발자가 작성한 코드를 사용하여 애플리케이션의 흐름을 만들어낸다.
이것이 Spring Framework의 핵심개념 중 하나인 IoC(Inversion Of Control,제어의 역전)이다.
❑ Spring Framework를 배워야 하는 이유
➤ Spring Framework란?
스프링 프레임워크는 Java 기반의 웹 애플리케이션을 개발하는데 필요한 프레임워크이다.
2004년 버전 1.0이 처음 릴리즈 된 이후로 Java 기반의 웹 애플리케이션을 개발하는데 있어 표준이라 해도 과언이 아닐만큼 대세가 되었다.
그런데 자바 기반의 웹 애플리케이션을 개발하기 위한 프레임워크는 스프링만 있는 것은 아니다. Apache Struts2, Apache Wicket, JSF(Java Server Faces), Grails 와 같은 자바 또는 JVM 기반의 웹 프레임워크들이 존재한다.
▶️ 그런데 왜 스프링 프레임워크가 각광받는 걸까?
대부분의 기업들이 기업용 Enterprise 시스템용 애플리케이션 개발에 있어 Framework를 선택할 때, 개발 생산성을 높이고 어떻게하면 유지보수를 더 용이하게 할 것인가에 많은 초점을 맞춘다. 스프링 프레임워크는 개발 생산성을 향상시키고 유지보수를 용이하게 해주고 그 이상도 달성할 수 있게 해준다.
*기업용 Enterprise 시스템 : 기업의 업무(조직의 업무, 고객을 위한 서비스 등)를 처리해주는 시스템, 대량의 사용자 요청을 처리해야 하기 때문에 서버의 자원 효율성, 보안성, 시스템의 안전성이나 확장성 등을 충분히 고려해서 시스템을 구축한다.
Spring Framework를 사용하는 이유는 이전의 기술들을 알아보면 이해할 수 있다.
➤ Spring Framework 이전의 기술들
▶️ JSP를 이용한 애플리케이션
JSP(Java server page)
백엔드/프론트엔드의 구분없이 코드에 html/Javascript, Java가 뒤섞여 있는 방식이다.
가독성이 떨어지고 유지보수도 매우 어렵다.
프론트엔드/백엔드를 구분하지 않았던 예전엔 양쪽을 모두 개발하는 개발자들이 많았기 때문에 이런 방법을 이용했다.
▶️ 서블릿(Servlet)을 이용한 애플리케이션
JSP 방식과 Spring에서도 내부적으로 Servlet 방식을 사용한다.
서블릿은 클라이언트 웹 요청 처리에 특화된 Java 클래스의 일종이다.
서블릿 방식을 이용한다는 의미는 서블릿을 위한 자바 코드가 클라이언트 측 코드에서
분리되어 별도의 자바 클래스로 관리된다는 것을 의미한다.
하는 일에 비해 코드가 너무 길어보인다는 단점이 있다.
▶️ Spring MVC를 이용한 애플리케이션
서블릿 방식의 코드를 Spring MVC 방식의 코드로 바꾸면 코드가 간결해진다.
서블릿 방식은 클라이언트의 요청에 담긴 데이터를 꺼내오는 작업을 개발자가 직접 코드로 작성해야하고, 캐릭터셋도 지정해주어야 한다.
하지만 Spring MVC 방식의 코드에서는 눈에 보이지 않지만 그런 작업들을 Spring에서 알아서 처리해준다.
그런데도 Spring 기반의 애플리케이션의 기본 도구를 잡는 설정 작업이 여전히 불편하다는 단점이 있다.
그래서 이러한 문제를 대부분 개선한 Spring Boot가 나왔다.
▶️ Spring Boot을 이용한 애플리케이션
이전 기술에서 구현한 것을 더 짧은 코드로 간결하게 작성할 수 있다.
Spring MVC에서 겪었던 설정의 복잡함을 Spring Boot에서는 찾아볼 수 없다.
Spring의 복잡한 설정 작업도 Spring이 대신 처리해주기 때문에 개발자는
애플리케이션의 핵심 비즈니스 로직에만 집중할 수 있게 되었다.
※ 심화 학습
자바 서블릿이란?
자바 서블릿 자체를 사용하는 기술은 현재 거의 사용하고 있지 않지만 Spring MVC같은 자바 기반의 웹 애플리케이션 내부에서 여전히 사용되고 있다.
서블릿 컨테이너란?
서블릿 기반의 웹 애플리케이션을 실행해주는 것부터 시작해서 서블릿의 생명주기를 관리하며, 쓰레드 풀을 생성해서 서블릿과 쓰레드를 매핑시켜 주기도 한다.
아파치 톰캣(Apache Tomcat)은 서블릿 컨테이너의 한 종류로써 Spring MVC 기반의 웹 애플리케이션 역시 기본적으로 아파치 톰캣에서 실행 된다.